Attention is all you need
代码都放在了github https://github.com/xuanzebi/Attention ,之后读论文如果遇到不错的其他attention机制也会继续更新。欢迎star~
attention
公式如下图,可以看到如果Q、K、V 都设置成对应一个文本的参数的话,就是self-attention。
Q K可以设置成对应不同词向量后的不同的参数,比如在问答中。比如aspect的情感分类Q可以设置成context,K则设置成aspect过embedding后的参数。具体可以看下方代码,通俗易懂。
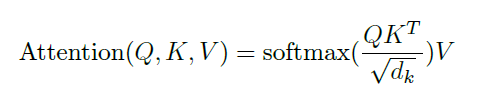
代码 keras
1 | class Attention(Layer): |
代码 tensorflow
1 | def attention_layer(from_tensor, |
transformer 网络结构代码
1 | def transformer_model(input_tensor, |
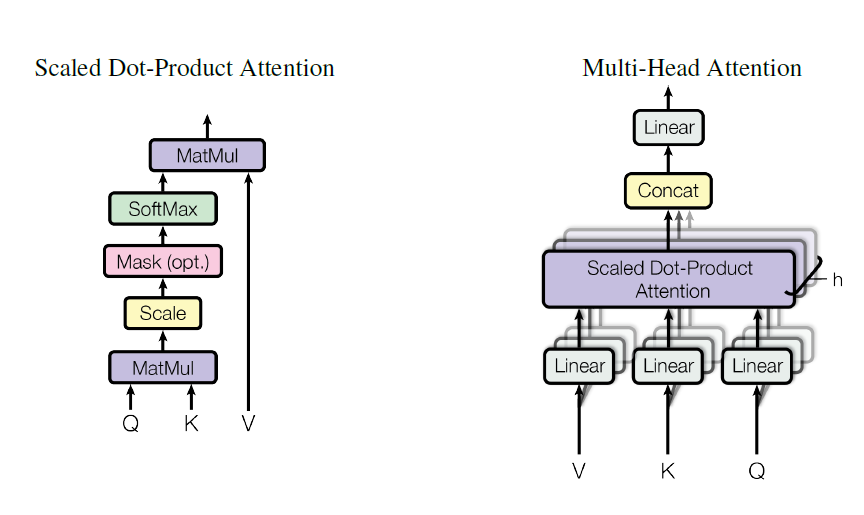
Multi-Head Attention (MHA) Intra-MHA Inter-MHA
最近看了一篇基于aspect的情感识别,其中的inter 和 Intra 多头attention不错。所以来写一下
Attentional Encoder Network for Targeted Sentiment Classification
论文网络结构
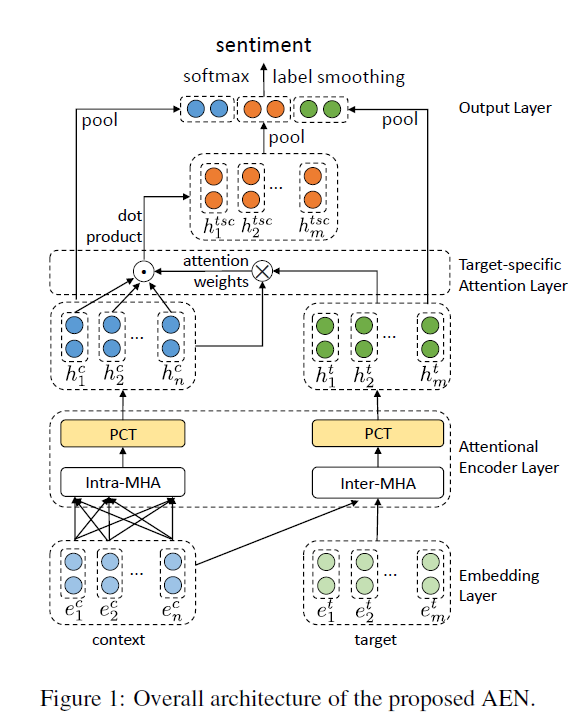
其中的Intra-attention、Inter-attention实现代码
1 | # -*- coding: utf-8 -*- |